数据服务的引擎 程序员视角下的数据处理服务
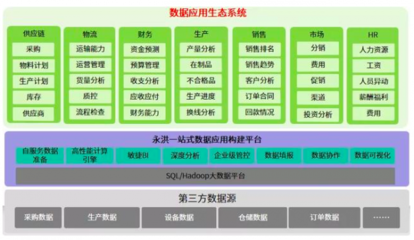
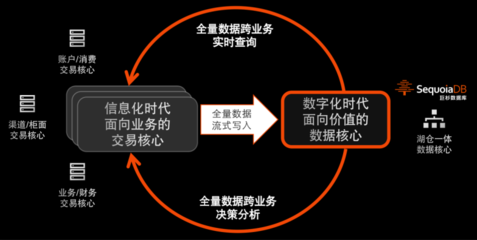
在构建数据中台的宏大图景中,如果说数据平台是地基与框架,那么数据处理服务无疑是驱动一切数据流动与价值转化的核心引擎。作为一名深度参与其中的程序员,我所理解的“数据处理服务”,远不止于简单的ETL工具或运行任务的代码集合,它是一个将原始数据转化为可信、可用、可服务资产的系统性工程,是连接数据孤岛与业务价值的桥梁。
一、 从“管道工”到“炼金术士”:角色的演变
传统开发中,程序员常自嘲为“数据管道工”,任务是将数据从A点搬到B点,并确保不“泄漏”。而在数据中台的数据处理服务范畴内,我们的角色更像是“数据炼金术士”。
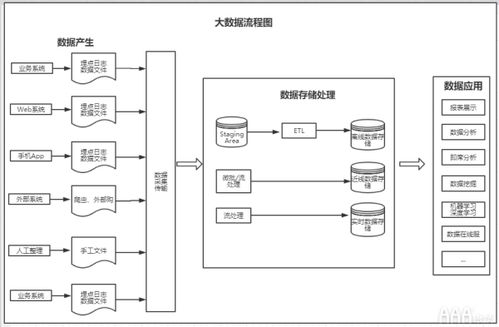
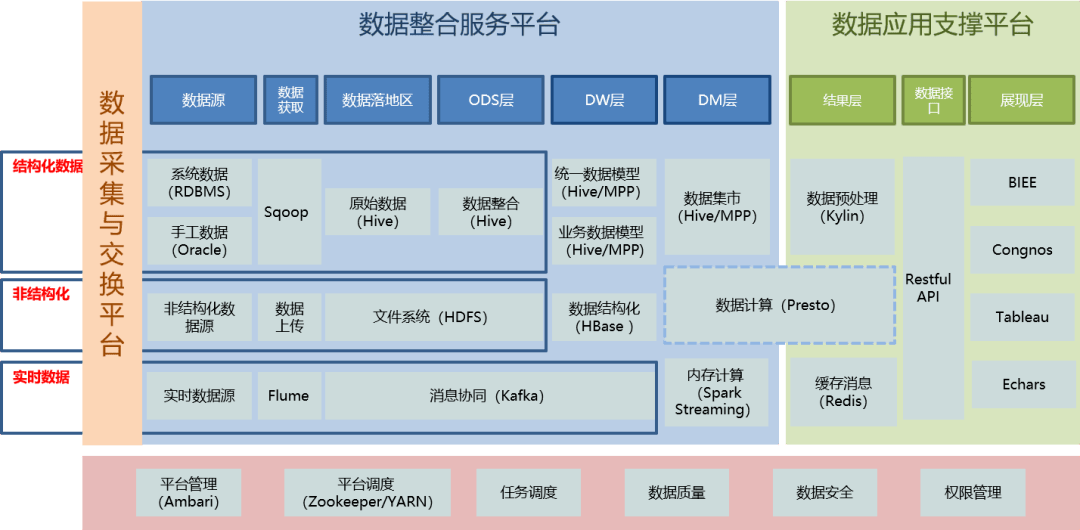
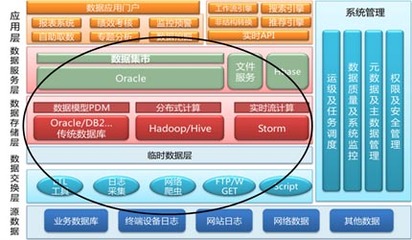
- 标准化与建模:我们不再仅仅搬运数据,而是首先定义数据的“语言”。这包括建立统一的数据标准、维度模型(如Kimball的星型模型、Data Vault等),并通过代码(如SQL、Spark、Flink作业)实现从杂乱无章的ODS层到主题明确、关联清晰的数仓(DW/DWD)或数据湖表的转化。一个设计良好的数据模型,是后续所有数据服务高效、准确的前提。
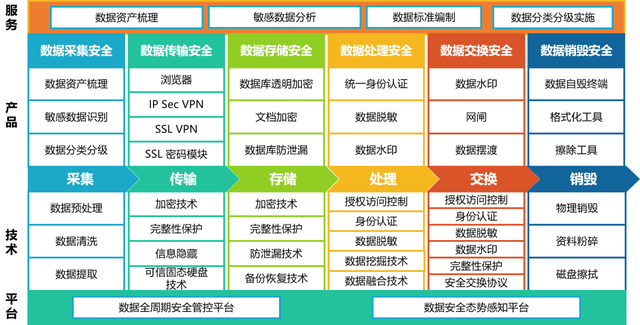
- 质量与血缘:我们在数据处理链路中嵌入质量检查规则(如非空校验、值域校验、一致性校验),让数据问题在加工过程中暴露并预警。通过技术手段(如解析SQL、记录任务日志)构建数据的血缘图谱,清晰描绘出数据从源头到最终服务的完整 lineage,这对于故障排查、影响分析和合规审计至关重要。
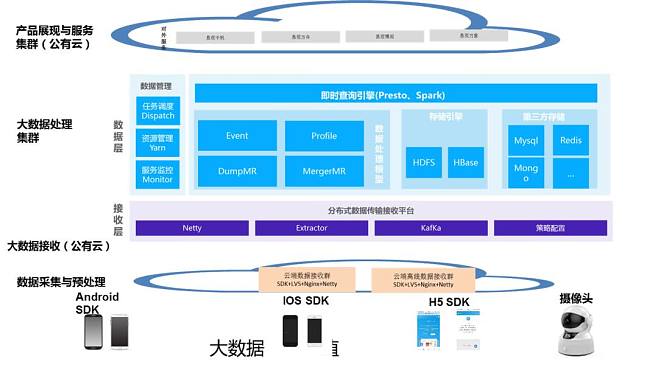
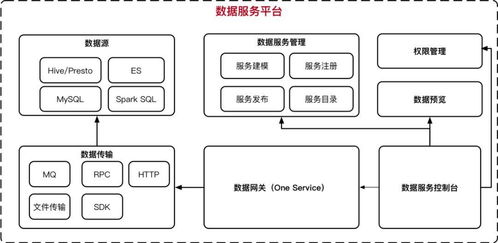
二、 核心组件:批流一体的处理架构
现代数据处理服务通常是批处理与流处理融合的架构,以满足不同业务场景的时效性要求。
- 批处理服务:面向T+1或周期性的海量数据加工。程序员需要熟练运用如Apache Spark、Hive等框架,编写高效、稳定的调度作业。挑战在于如何优化资源利用率、处理数据倾斜、保证任务重试的幂等性,以及管理复杂的依赖关系。一个健壮的批量任务调度平台(如DolphinScheduler、Airflow)是程序员的好帮手。
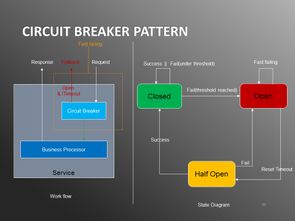
- 流处理服务:满足实时监控、实时推荐等场景。这要求我们深入理解Apache Flink、Kafka Streams等流式计算引擎,处理乱序数据、维护状态、实现精确一次(Exactly-Once)语义。流处理代码需要更高的容错性和低延迟保障。
将两者结合(Lambda或Kappa架构),实现“一份逻辑,两种执行”,是当前数据处理服务设计的前沿方向,也对程序员的架构设计能力提出了更高要求。
三、 工程化实践:代码即资产
在程序员眼中,数据处理服务本身就是重要的软件产品,需要遵循严格的工程化实践。
- 代码化管理:数据处理逻辑(SQL、UDF、配置)应全部纳入版本控制系统(如Git)。这带来了可追溯、可协作、可回滚的巨大好处,彻底改变了以往在调度界面配置黑盒任务的模式。
- 可复用与模块化:将通用的数据清洗、转换、维表关联逻辑抽象成公共函数或组件,通过参数化驱动不同业务线的使用。这提升了开发效率,也保证了处理逻辑的一致性。
- 测试与部署:为数据处理作业编写单元测试(测试转换逻辑)、集成测试(测试端到端流水线)变得可能且必要。结合CI/CD流水线,实现数据处理任务的自动化测试与发布,确保上线质量。
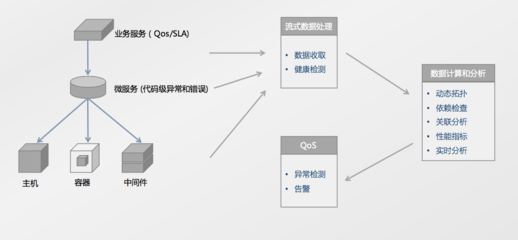
- 运维与监控:强大的监控体系是服务的“眼睛”。我们需要关注任务运行时长、资源消耗、数据产出时效和质量指标。一旦出现异常,能快速定位是代码bug、资源不足还是源数据问题。
四、 挑战与未来:迈向智能化与自助化
尽管技术栈日益成熟,挑战依然存在:如何管理爆炸式增长的数据资产和计算成本?如何让业务人员能更自助地定义数据处理逻辑而不失规范性?
未来的数据处理服务将更加强调:
- 智能化:利用AI进行自动化的异常检测、任务优化建议(如动态调整并行度)、甚至智能生成部分ETL代码。
- SQL化与低代码化:通过更强大的SQL引擎和可视化拖拽界面,降低业务分析师参与数据加工的门槛,但背后仍需程序员构建稳固、高性能的执行引擎来支撑。
- 云原生与Serverless:数据处理服务将更深地与云基础设施结合,按需弹性伸缩,让程序员更专注于业务逻辑而非集群运维。
###
在数据中台的体系中,数据处理服务是默默耕耘的“后台英雄”。它不直接面向最终用户,却决定了所有数据应用体验的下限与上限。对于程序员而言,构建数据处理服务不仅需要精湛的分布式计算技术和架构设计能力,更需要一种对数据本身的热爱、对业务价值的深刻理解,以及将混沌数据点石成金的工匠精神。当一条条高效、可靠的数据流水线昼夜不息地运转,将原始数据转化为驱动决策、赋能创新的清泉时,便是我们代码价值最生动的体现。
如若转载,请注明出处:http://www.weijiesong.com/product/8.html
更新时间:2026-04-22 04:35:07