日处理20亿数据系统架构 高效数据处理服务的设计与实践
在当今大数据时代,日处理20亿条数据的系统已成为众多互联网企业与科技公司的核心需求。这样的系统不仅需要处理海量数据,还需保证高吞吐量、低延迟、高可用性与可扩展性。本文将深入探讨一个高效数据处理服务的关键架构设计、技术选型与优化策略。
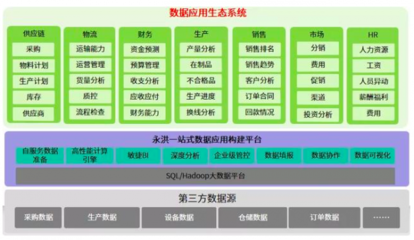
一、核心架构设计原则
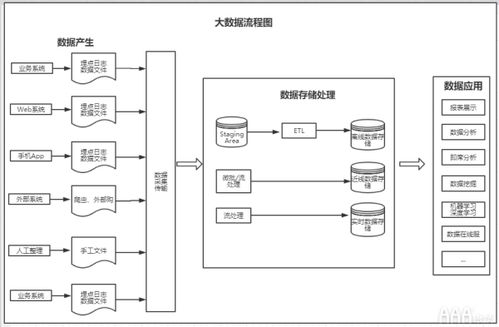
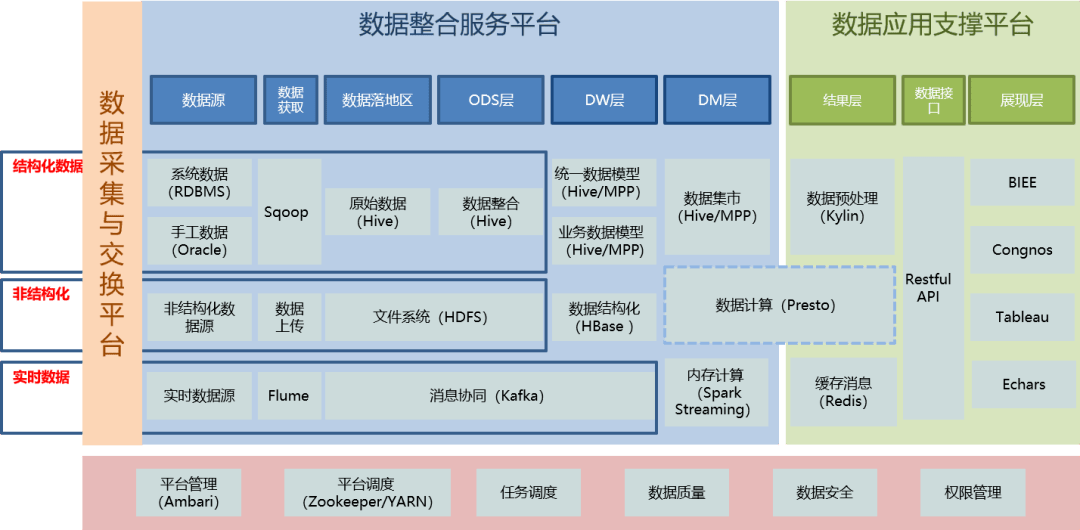
- 分层与解耦:系统应分为数据采集层、存储层、处理层和查询层,各层通过标准化接口通信,便于独立扩展与维护。
- 水平扩展能力:采用分布式架构,避免单点瓶颈,支持通过增加节点线性提升处理能力。
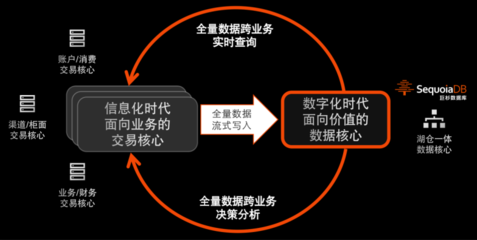
- 最终一致性:在CAP定理中优先保证可用性与分区容错性,通过异步处理与补偿机制确保数据最终一致。
- 流批一体化:结合流处理(实时)与批处理(离线),满足不同业务场景对时效性的要求。
二、关键技术组件与选型
- 数据采集与接入:
- 使用Apache Kafka或Pulsar作为消息队列,缓冲高并发数据流入,实现削峰填谷。
- 部署多个生产者客户端,通过负载均衡将数据分发至不同分区。
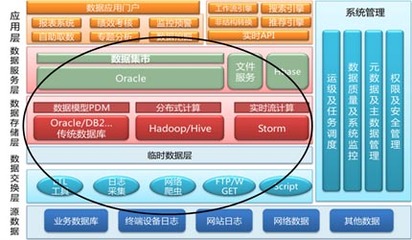
- 数据存储:
- 原始数据存储:采用HDFS或云对象存储(如AWS S3、阿里云OSS),提供高可靠、低成本的海量存储。
- 索引与查询存储:结合Elasticsearch(全文检索)、ClickHouse(OLAP分析)与HBase(随机读写),根据查询模式优化存储结构。
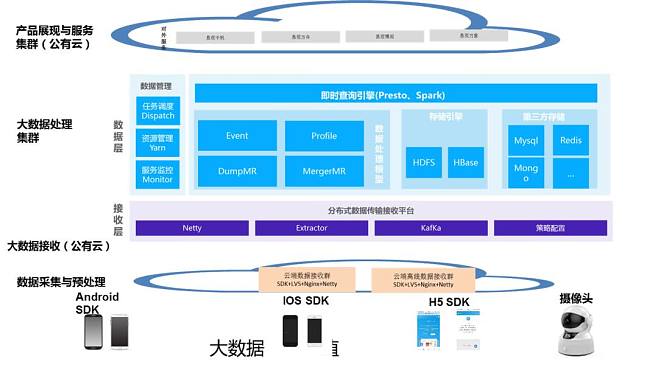
- 数据处理引擎:
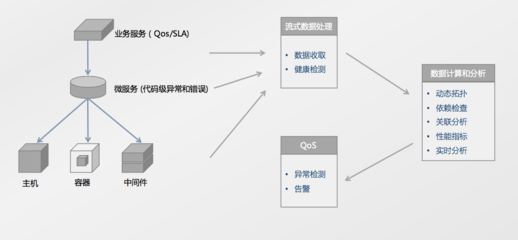
- 流处理:选用Apache Flink或Spark Streaming,支持状态管理与Exactly-Once语义,实现实时计算与告警。
- 批处理:利用Apache Spark或Hive进行离线ETL、数据清洗与聚合分析。
- 数据湖技术:Delta Lake或Apache Iceberg确保ACID事务,简化数据版本管理。
- 资源调度与协调:
- 基于Kubernetes部署容器化服务,实现弹性伸缩与快速故障恢复。
- 使用ZooKeeper或etcd进行集群协调与配置管理。
三、性能优化策略
- 数据分区与分片:
- 按时间(如天/小时)或业务键(如用户ID)对数据进行分区,缩小单次处理范围。
- 合理设置Kafka分区数与Spark/Flink并行度,充分利用集群资源。
- 计算与存储分离:
- 存储层独立扩展,避免计算任务竞争I/O资源。
- 采用列式存储格式(如Parquet、ORC),提升压缩率与查询效率。
- 内存与缓存优化:
- 配置Spark/Flink堆外内存,减少GC开销。
- 使用Redis或Memcached缓存热点数据,加速实时查询。
- 异步与并行处理:
- 将非关键路径异步化(如写入审计日志),避免阻塞主流程。
- 批处理任务采用DAG调度,最大化并行执行。
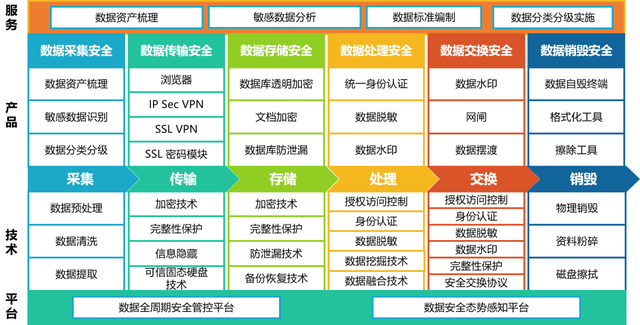
四、高可用与监控保障
- 多活与容灾:在多个数据中心部署服务,通过数据复制与流量切换应对区域性故障。
- 全链路监控:集成Prometheus、Grafana与ELK栈,实时跟踪系统健康度、吞吐量、延迟等指标。
- 自动化运维:通过CI/CD流水线部署变更,结合Chaos Engineering进行故障演练,提升系统韧性。
五、挑战与未来展望
日处理20亿数据的系统仍面临数据倾斜、成本控制与隐私合规等挑战。随着硬件升级(如NVMe SSD、RDMA网络)与软件生态演进(如向量数据库、AI集成),数据处理服务将向更智能、更高效的方向持续进化。
构建大规模数据处理系统是一项复杂工程,需在架构设计、技术选型与运维实践中不断权衡与迭代。通过本文所述的策略,企业可建立起稳定、可扩展的数据处理服务,为业务创新提供坚实的数据基石。
如若转载,请注明出处:http://www.weijiesong.com/product/22.html
更新时间:2026-04-22 12:00:10