大数据架构图 数据处理服务的核心引擎
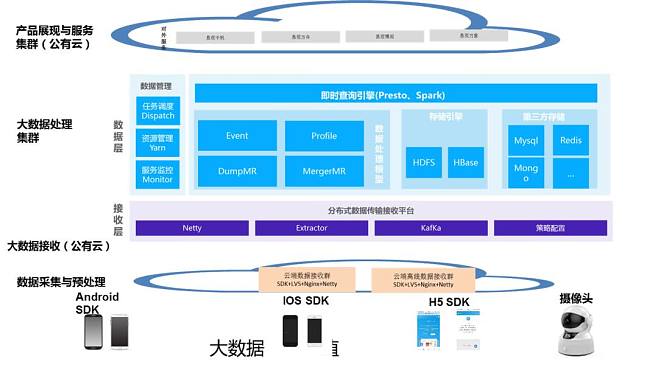
当我们搜索“大数据架构图”时,呈现的不仅仅是一张张复杂的图表,更是现代数据处理服务的蓝图与灵魂。这些架构图揭示了数据从原始状态到价值洞察的完整旅程,而数据处理服务,正是驱动这一旅程的核心引擎。
一、大数据架构图的层次解析
典型的大数据架构图通常呈现为一个分层的、可扩展的体系,自上而下或自流程角度,一般包含以下核心层次:
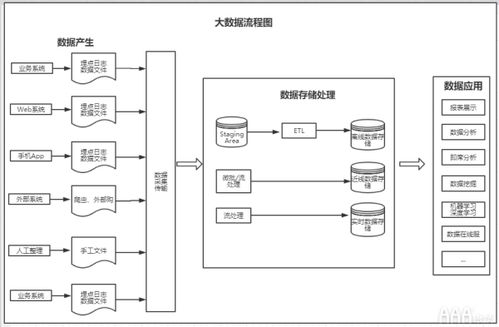
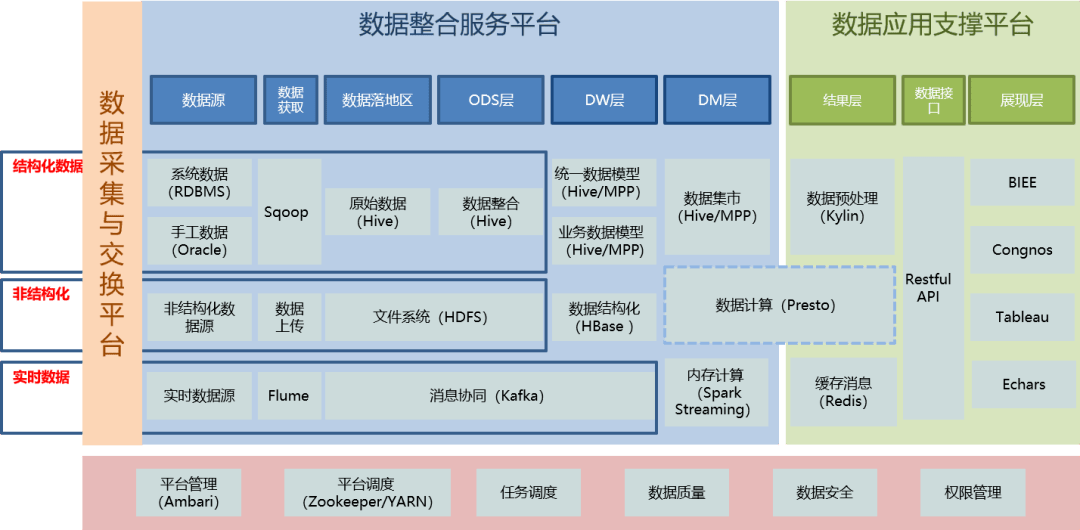
- 数据源与采集层:架构的起点。图示中会包含各类数据源,如数据库、日志文件、物联网传感器、社交媒体流等。数据处理服务在此层的体现是数据采集工具(如Flume, Kafka, Sqoop),它们负责实时或批量地将数据“吸入”系统,确保数据入口的可靠性与高效性。
- 数据存储层:海量数据的蓄水池。架构图中,分布式文件系统(如HDFS)和NoSQL数据库(如HBase, Cassandra)是常见图标。数据处理服务在此扮演“仓库管理员”的角色,通过数据存储与管理服务,决定数据以何种格式、何种分区策略存储,以优化后续的访问与分析效率。
- 数据处理与计算层:架构的核心动力区。这是图中最“繁忙”的部分,通常包含批处理(如MapReduce, Spark)、流处理(如Storm, Flink, Spark Streaming)和交互式查询(如Hive, Impala)等多种计算框架。数据处理服务在此具体化为计算引擎,它根据业务需求(是分析历史全量数据还是实时监控数据流)调度合适的计算框架,执行数据清洗、转换、聚合和复杂分析任务。
- 数据服务与接口层:价值输出的门户。架构图顶端会展示各类应用,如BI报表、数据API、机器学习模型。数据处理服务在此层提供数据查询、封装和交付服务(如通过Presto, Druid提供低延迟查询,或通过微服务API提供数据产品),将处理后的结构化数据高效、安全地输送给最终用户和应用程序。
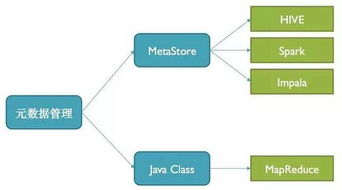
- 管理与监控层:贯穿全局的神经系统。在优秀的架构图中,这不是一个独立的层,而是覆盖全流程的组件,包括资源管理(YARN, Kubernetes)、元数据管理、数据治理、安全控制和性能监控。数据处理服务的可靠性、可运维性和安全性全靠这一层的服务来保障。
二、数据处理服务:架构图中的“活”的灵魂
如果将大数据架构图比作城市的规划图,那么数据处理服务就是其中运行的水、电、交通网络。它并非一个单独的图标,而是融入每一层的能力:
- 在采集层,它是数据管道服务,确保数据流不中断、不丢失、不重复。
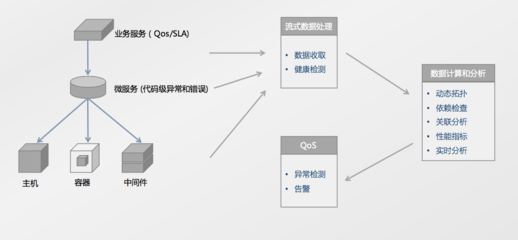
- 在存储与计算层,它是资源编排与任务调度服务,在复杂的分布式环境中高效利用集群资源,协调成千上万的计算任务。
- 在分析层,它是统一的数据处理平台服务(如云厂商提供的EMR、Databricks等),将多种计算框架整合,为用户提供一键式数据处理能力。
- 在全程,它是数据质量与治理服务,监控数据血缘、保证数据一致性、执行数据安全策略。
三、从架构图到服务化:现代数据平台的演进趋势
早期的大数据架构图聚焦于技术组件的堆叠,而现代的架构设计越来越强调“服务化”(Data as a Service)。这意味着:
- 抽象与简化:用户(数据开发者、分析师)无需深究底层计算集群的细节,通过服务界面即可提交处理任务、获取结果。
- 弹性与成本优化:数据处理服务可以按需动态伸缩资源,实现计算与存储分离,从而优化性能与成本。云原生架构(对象存储+容器化计算)在此趋势中成为主流。
- 实时化与智能化:架构图中流处理路径与批处理路径趋于融合(Lambda/Kappa架构),数据处理服务能够支撑从实时风控到离线报表的全面需求。AI/ML工作流被无缝集成,数据处理服务自动为模型训练准备特征数据。
###
因此,解读一张“大数据架构图”,关键在于理解其中隐含的数据处理服务流。它勾勒了数据流动的管道,标定了计算发生的枢纽,并最终指明了价值输出的方向。对于企业和开发者而言,选择或构建一个大数据架构,本质上是选择一套能够满足其性能、成本、易用性需求的、完整的数据处理服务体系。这张图,是数据处理服务战略意图最直观的宣言。
如若转载,请注明出处:http://www.weijiesong.com/product/16.html
更新时间:2026-05-28 15:41:03